Building a web scraper that downloads my anime for me
Download Multiple Anime Episodes Using Beautiful Soup
Anime❤, the one thing in my heart after programming, why would everyone not love anime, assuming you are like me who wants most things cheap and easy, then I would believe you also prefer downloading free anime to watch offline for convenience. You’ve found the anime you would like to download and then you realize “damn!, it’s over a hundred episodes long”, we don’t want to open a hundred-plus URL to download each episode one by one, NO!!, we are lazy, we love things cheap and easy, there’s got to be a better way. Right then you look above you and notice a blinding light slowly approaching you from a distance, as you try to squint your eyes to get a visible glimpse of what is coming, you think “IT’S A BIRD!”, “IT’S A PLANE”, “NO!!, it’s BeautifulSoup” to the rescue😂. And now with BeautifulSoup, you don’t have to open a hundred URLs painfully.
So now we are going to build our simple anime-downloader web scrapper to do just that, for this project we would be using the gogoanime site whatever it may be at the point of reading since the top-level domain is changed often
So here’s an overview of what we’ll be doing:
- Visit the site to inspect the HTML structure
- Write code😋
Requirements
- Basis understanding of python.
- For this project, I made use of the internet download manager(IDM) library, because I found downloading easier with IDM than trying to use the python download manager library; pySmartDL, which means you will need to have IDM installed on your system, or if you can figure out how to make use of pySmartDL you can do so, and also reach out to me on how you implemented it. Thanks
LET’s GO!
Inspect HTML structure
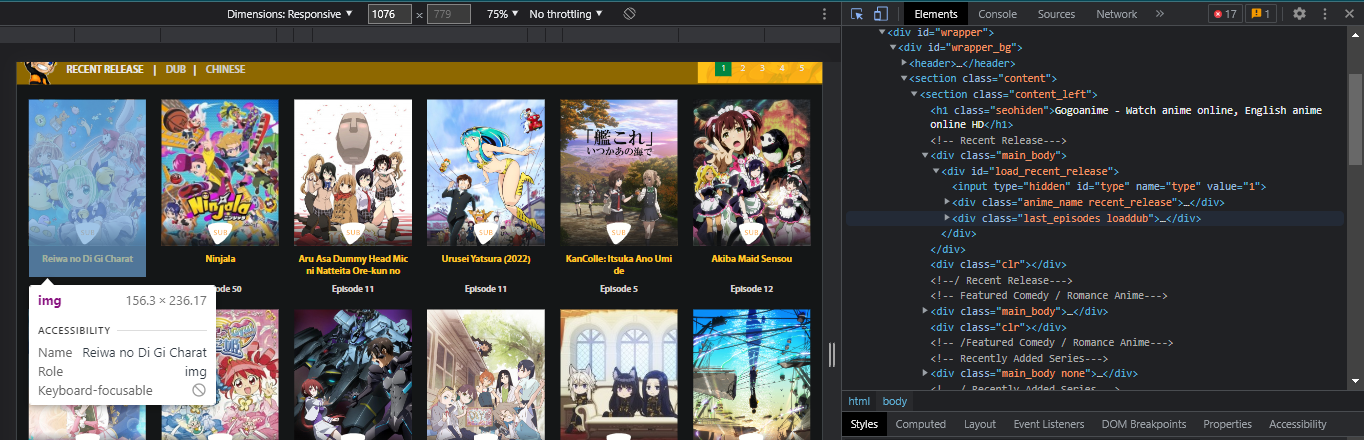
To find what you are looking for, select an anime and navigate to the download page of any episode, then inspect the page to see when the download links are located, to see download links, you must be logged in.

That should be what you're looking for, you can snoop around the inspect element to understand the page structure.
Write CODE!
The code is quite long so your gonna have to take your time, I will be using pycharm IDE for the project but you can use any IDE of your choice
- Create Virtual Environment: If you are using pycharm, creating a new project should automatically do that for you, else you can open cmd, go to your project path and run this command;
python3 -m venv venvthen activate the venv using
venv\scritps\activate2. Install Libraries: If you are using pycharm, you can search for them and install them by clicking the python packages on the bottom bar;

or install them using cmd.
3. Libraries:
from bs4 import BeautifulSoup as bs
from decouple import config
from lxml import html
import requests
from os import path
from idm import IDMan
import time
import re
downloader = IDMan()4. URL variables:
# input first URL
print('Input the link of the first anime episode you wish to download')
animeUrl = input('first episode of url: ')
# URLs
# get the root url
rootUrl = re.search(
r"[A-Za-z0-9]+://[A-Za-z0-9]+\.[a-zA-Z]+/", animeUrl).group(0)
# get the login url
login_url = rootUrl + 'login.html'
# get name of anime from link
animeNameFromLink = re.search(
r"([A-Za-z0-9]+(-[A-Za-z0-9]+)+)", animeUrl).group(0)
animeName = re.sub(r"-episode-\d+$", "", animeNameFromLink)
# create the download url
downloadUrl = re.sub(r"\d+$", "", animeUrl)
# create download filepath
filePathAnimeName = re.sub(r"-episode-\d+$", "", animeNameFromLink)the “animeUrl” takes in the URL of the first episode or just any episode which is used to generate the URLs of all other episodes we wish to download, the “filePathAnimeName” extracts the name of the anime from the link to use in saving the anime.
5. Input Variables:
# input variables
file_path = input('input download filepath: ')
firstEpd = int(input("input first episode to download: "))
lastEpd = int(input("input last episode to download: "))
print("Select your preferred Quality")
print("1 for 360p, 2 for 480p, 3 for 720p, 4 for 1080p")
pickQuality = int(input("select quality: "))
quality = {1: "640x360", 2: "854x480", 3: "1280x720", 4: "1920x1080"}
email = config('EMAIL')
password = config('PASSWORD')For your email and password, they should be stored in a .env file since those are sensitive information, we would get to that in a bit. For the “file_path” copy and input the path of where you want the anime to be saved from your file-explorer, ie; C:\Users\user\Videos, the others are pretty self-explanatory.
6. Functions:
function #1: IDM downloader function
# function to download anime
def downloadLink(link, filepath, filename):
downloader.download(link, filepath, output=filename, lflag=2)function #2: a function that gets the download link from the Html page of the anime
# get download links
def getLinks(url, qualitySelected):
# dictionary of anime quality their links
links_dict = {}
# get html
r = s.get(url)
soup = bs(r.text, 'html.parser')
links = soup.find_all("div", class_="cf-download")
selected_quality = selectQuality(qualitySelected)
# get the download links from the html
for link in links:
# loops through all quality links
for a in link.find_all('a', href=True):
# get selected quality link
if selected_quality == a.text.strip():
urls = (a['href'])
links_dict[a.text] = urls
return links_dictfunction #3: a function that selects the quality of the anime you choose:
# get the selected quality
def selectQuality(qualitySelected):
for x, y in quality.items():
if qualitySelected == x:
return yfunction #4: a function that generates the episode links and also file-path and name to save the anime
# get the episode urls and download path of the anime
def getAnimeUrls(start, end, v_quality):
# stores the generated episode links with its file-path and episode name
animeUrl = {}
quality_selected = selectQuality(v_quality)
for i in range(start, end + 1):
url_list = downloadUrl + str(i)
# filename has to match the name of the episode sent by the server else idm would prompt for rename
file_name = f'({quality_selected}-gogoanime)' + \
animeName + '-episode-' + str(i) + '.mp4'
ep_path = path.normpath(file_path + "/" + filePathAnimeName)
ep_path_and_name = (ep_path, file_name)
animeUrl[url_list] = ep_path_and_name
return animeUrlfunction #5: function to download the anime from the getAnimeUrls
# function to download the animes
def downloadAnime(startEp, endEp, qualitySelected):
# get selected episodes anime urls
urls = getAnimeUrls(startEp, endEp, qualitySelected)
# loops through all urls
for epUrl, ePathAndName in urls.items():
downloadLinks = getLinks(epUrl, qualitySelected)
# path to save the anime on your system
epPath = ePathAndName[0]
# name the anime is saved with
name = ePathAndName[1]
if len(downloadLinks) == 0:
print(f"EP {epUrl} NOT FOUND ")
continue
# download anime
for link in downloadLinks.values():
# delay next download function call
if epUrl != list(urls.keys())[-1]:
print(f'about to download {name}')
downloadLink(link, epPath, name)
print('not last anime')
time.sleep(20)
elif epUrl == list(urls.keys())[-1]:
print(f'last anime {name}')
downloadLink(link, epPath, name)
print("downloading")the time.sleep() is there, so as not to load their servers with a load of requests instantly.
function #6: main function
def main(firstEpd, lastEpd, pickQuality):
downloadAnime(firstEpd, lastEpd, pickQuality)7. The “.env” file:
Open a new file in your project folder and name it “.env”, in the file you can write;
EMAIL=youremail
PASSWORD=yourpasswordMake sure if you are uploading any project to a repository like GitHub, make sure to have your .env file specified in your .gitignore folder so as not to upload sensitive information online.
8. Requests:
Finally, use requests to make a post request to log in and use the session
s = requests.Session()
result = s.get(login_url)
tree = html.fromstring(result.text)
# extract hidden token
token = list(set(tree.xpath("//input[@name='_csrf']/@value")))[0]
payload = {
'email': email,
'password': password,
'_csrf': token
}
p = s.post(login_url, data=payload)
main(firstEpd, lastEpd, pickQuality)
s.close()the token is a hidden token generated in the Html script which is used alongside the post request, then you call the function when the download is done and the session is closed.
And with that, we have created our anime downloader.
Conclusion
BeautifulSoup is just one of many tools used for Web-scraping with other players such as Scrapy and Selenium, which are quite different but the same. Most of the whole process boils down to the programming logic, which you can improve on, adjust and add more features, the possibilities are endless.
It is important to also consider certain topics in web scraping such as ethics, proxies, header and other common practices used to secure yourself and build better scrapers.
You can view the full code on my GitHub, my name is Ben and Thank You very much.
