Check out this New and Faster Web Scraping Combo
Say goodbye to BeautifulSoup and Requests

BeautifulSoup and Requests, the two most commonly used libraries when it comes to web scraping. But for this post, we will take a look at the two newcomer combo in web scraping
Selectolax is a light-weight python library written on top of a C package called modest, specifically built for parsing HTML documents and the second HTTPX, a new HTTP client for python which provides sync and async support natively
Let's jump right into how to make use of HTTPX and Selectolax, first you’ll need to install both libraries.
pip install httpx
pip install selectolaxImport the libraries and also the python dataclasses library to easily arrange our data
import httpx
from selectolax.parser import HTMLParser
from dataclasses import dataclass, asdictWe’ll make a basic request using HTTPX and parse its contents with Selectolax
r = httpx.get('https://www.scrapethissite.com/pages/simple/')
tree = HTMLParser(r.content)So now let’s look at a couple of things we can do with Selectolax using the most common methods you will probably use 80% of the time, before then writing our little script.
>>> node = tree.css_first(".col-md-12 h1") # returns the node of the first match of the css class
>>> node
<Node h1>
>>> node.attributes # returns a dictionary of attributes that belongs to the current node
{} # has no attribute
>>> tree.css_first(".col-md-12 h1").text(strip=True) # returns the text in the node
'Countries of the World: A Simple Example250 items'
>>> tree.css(".col-md-12") # retures a list of nodes that matches
[<Node div>, <Node div>, <Node div>, <Node div>]
>>> for item in tree.css(".col-md-12"):
item.text(strip=True) # loop through your list of items
>>> tree.head # returns head node
<Node head>
>>> tree.head.text(strip=True) # returns the text
'Countries of the World: A Simple Example | Scrape This Site | A public sandbox for learning web scraping'while there are a lot more methods available, it's certain that for most or a number of your tasks if it's just getting text out of HTML this would do, so let's put it all together and print out useful information.
import httpx
from selectolax.parser import HTMLParser
from dataclasses import dataclass, asdict
r = httpx.get('https://www.scrapethissite.com/pages/simple/')
tree = HTMLParser(r.content)
head = tree.head.text(strip=True)
@dataclass
class Country:
name: str
capital: str
population: int
area: float
countries = tree.css(".col-md-4.country")
print(head)
for country in countries:
info = Country(
name = country.css_first("h3.country-name").text(strip=True),
capital= country.css_first("span.country-capital").text(strip=True),
population= country.css_first("span.country-population").text(strip=True),
area= country.css_first("span.country-area").text(strip=True),
)
print(asdict(info))returns
'Countries of the World: A Simple Example | Scrape This Site | A public sandbox for learning web scraping'
{'name': 'Andorra', 'capital': 'Andorra la Vella', 'population': '84000', 'area': '468.0'}
{'name': 'United Arab Emirates', 'capital': 'Abu Dhabi', 'population': '4975593', 'area': '82880.0'}
...Conclusion
Just having a look at Selectolax, its syntax looks pretty much the same as BeautifulSoup, so you might wonder what are its upside and necessary use cases like stated earlier it is built on top of a C library called modest which implicitly means it performs faster than BeautifulSoup and it is also lightweight given that it's built specifically for HTML parsing, so it is lighter and faster than BeautifulSoup, though a couple of times BeautifulSoup would still suffice if speed is not an issue. Its use case will be more applicable if you plan on scaling your project without sacrificing performance.
Here is a benchmark measurement of Selectolax and BeautifulSoup
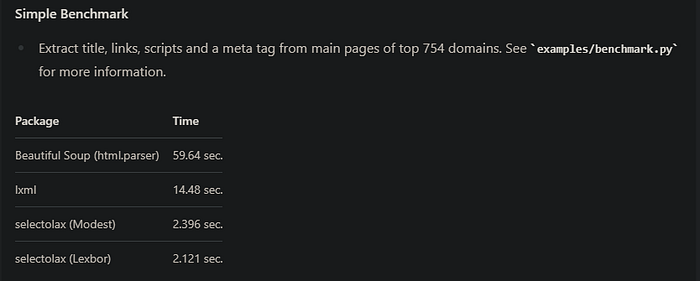
You can check it out on morioh.com.
While the HTTPX library may not be as important in most cases the major difference between HTTPX and Request would be its native async support.
Thank You for your time.